Big Query
For those who are into data, Big Query is a great choice if you would like a database but database management is not your thing.
Big Query acts as a database in all of the key ways that matter. It is a persistant dat store of tabular data that allows you to run SQL against it.
However with Big Query there is no provisioning servers, patching database upgrades or worries about the compute power to run the queries.
In Google’s own words Big Query is:
A serverless, highly scalable, and cost-effective cloud data warehouse
Pandas
Pandas is the go to tool for data analysis with python.
For an introduction to the Pandas library see this post: https://marquinsmith.com/2017/09/06/a-great-introduction-to-data-analysis-in-python-with-pandas/
Down to business
Requirements
- Google Cloud Platform account
- Python3
Big Query lives inside Google Cloud Platform projects and we will need a service account key to interact with it.
The video below shows the following:
- how to set up a new project
- create a service account and download json key
- create a new dataset (where tables of data will live)
On to the code
Associated Github repo: https://github.com/quincysmiith/bq-write-play
Credentials are needed to interact with Big Query using python, the snippet below shows how to set up the credentials:
from google.oauth2 import service_account
# create Google credentials from service account json file
service_account_json = "file/path/to/json_service_key.json"
credentials = service_account.Credentials.from_service_account_file(
service_account_json,
)
The pandas function to_gbq can then be used to load data in to Big Query
import pandas as pd
### create dataframe ###
# column names
my_columns = ["sepal_length", "sepal_width", "petal_length", "petal_width", "class"]
# load iris data
data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
data = pd.read_csv(data_url,
header = None,
names = my_columns)
# write to Big Query
data.to_gbq("an_example_dataset.iris",
project_id=project_id,
if_exists = "replace",
credentials=credentials)
In Big Query the iris data will be stored in a table called iris in the ‘an_example_dataset’ dataset
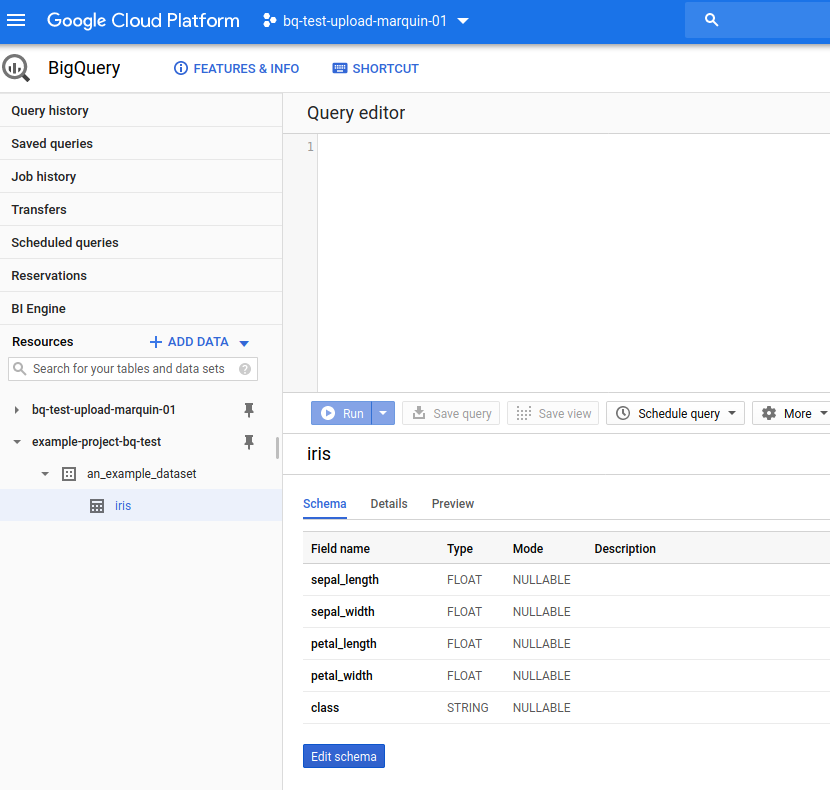
While not explicitly imported it is necessary to have pandas-gbq installed.
In my example on github the packages I manually installed are:
pandas
pandas_gbq
python-dotenv
google-auth
jupyterlab
It is also possible to read from Big Query with pandas
# read from Big query
q = """
SELECT * FROM `example-project-bq-test.an_example_dataset.iris`
WHERE class='Iris-versicolor';
"""
out_data = pd.read_gbq(q,
project_id=project_id,
credentials=credentials,
progress_bar_type=None)

One thought on “Interacting with Big Query using pandas”