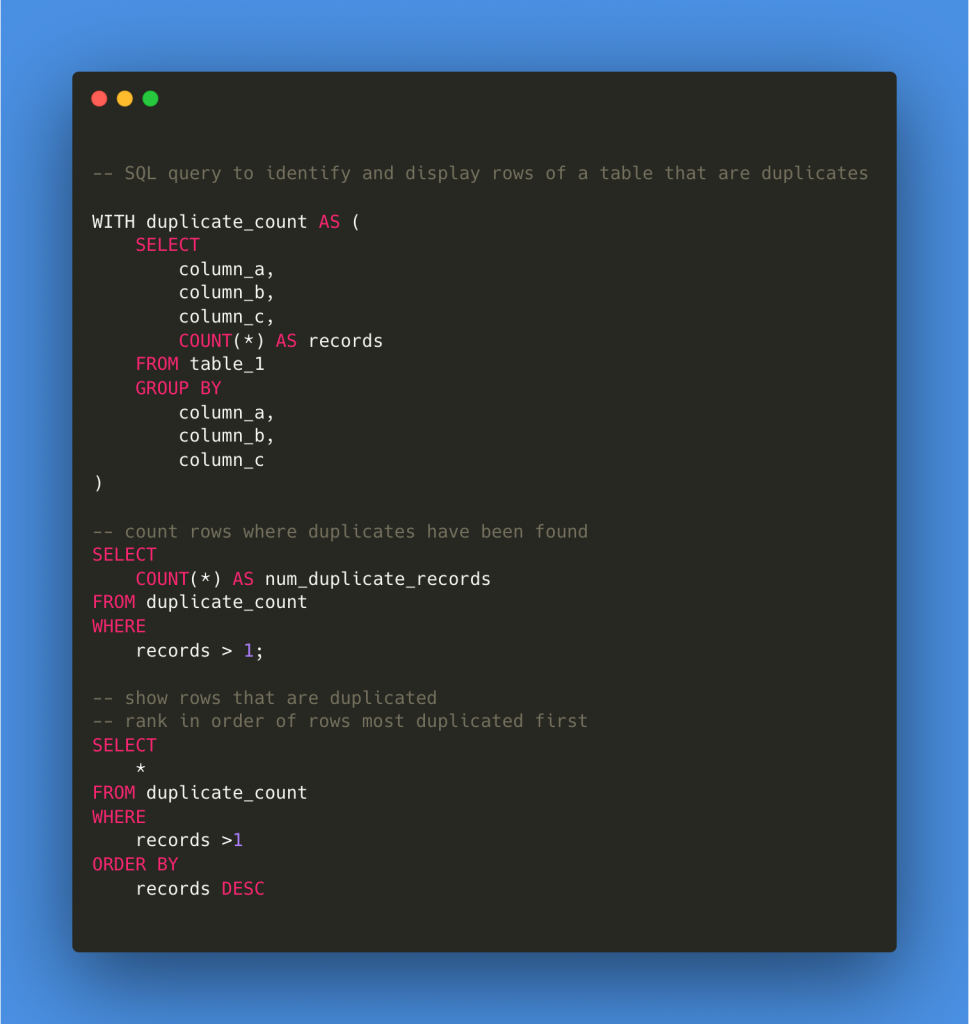
-- SQL query to identify and display rows of a table that are duplicates
WITH duplicate_count AS (
SELECT
column_a,
column_b,
column_c,
COUNT(*) AS records
FROM table_1
GROUP BY
column_a,
column_b,
column_c
)
-- count rows where duplicates have been found
SELECT
COUNT(*) AS num_duplicate_records
FROM duplicate_count
WHERE
records > 1;
-- show rows that are duplicated
-- rank in order of rows most duplicated first
SELECT
*
FROM duplicate_count
WHERE
records >1
ORDER BY
records DESC
